
Preamble
import numpy as np # for multi-dimensional containers
import pandas as pd # for DataFrames
import plotly.graph_objects as go # for data visualisation
Introduction
Objective functions are perhaps the most important part of any Evolutionary Algorithm, whilst simultaneously being the least important part too. They are important because they encapsulate the problem the Evolutionary Algorithm is trying to solve, and they are unimportant because they have no algorithmic part in the operation of the Evolutionary Algorithm itself.
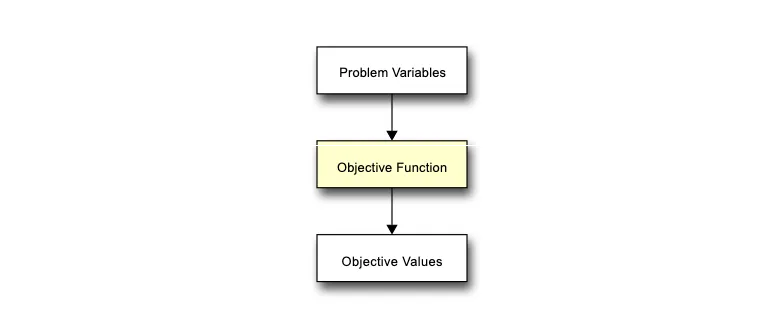
Put simply, objective functions expect some kind of solution input, i.e. the problem variables, and they use this input to calculate some output, i.e. the objective values. These objective values can be considered to be how the problem variables of a solution scored with respect to the current problem. For example, the input could be variables that define the components of a vehicle, the objective function could be a simulation which tests the vehicle in some environment, and the objective values could be the average speed and ride comfort of the vehicle.
In the figure below, we have highlighted the stage at which the objective function is typically invoked - the evaluation stage. It is after this that we find out whether a potential solution to the problem performs well or not, and have some idea about trade-offs between multiple solutions using the objective values. The stage that typically follows this is the termination stage, where we can use this information to determine whether we stop the optimisation process or continue.
Objective Functions in General
Let's have a quick look at what we mean by an objective function. We can express an objective function mathematically.
Before we can talk about this, we need to explain what
Let's asume that the number of decision variables for a problem is 8 so, in this case,
D = 8
x = np.random.rand(D)
print(x)
[0.7409217 0.64042696 0.37010243 0.46896916 0.56932005 0.65240768 0.19321112 0.27596008]
Now we have a single solution consisting of randomly initialised values for
Note
When running this notebook for yourself, you should expect the numbers to be different because we are generating random numbers.
Let's have a look at
We can implement such an objective function in Python quite easily.
def f(x):
f1 = np.sum(x) # Equation (3.1)
f2 = np.prod(x) # Equation (3.2)
return np.array([f1, f2])
Now let's invoke this function and pass in the solution
Which translated to Python will look something like the following.
y = f(x)
print(y)
[3.91131918e+00 1.63103045e-03]
This has returned our two objective values which quantify the performance of the corresponding solution's problem variables. There is much more to an objective function than what we've covered here, and the objectives we have defined here are entirely arbitrary. Nonetheless, we have implemented a two-objective (or bi-objective) function which we may wish to minimise or maximise.
Let's use Python to generate 50 more solutions
objective_values = np.empty((0, 2))
for i in range(50):
x = np.random.rand(8)
y = f(x)
objective_values = np.vstack([objective_values, y])
# convert to DataFrame
objective_values = pd.DataFrame(objective_values, columns=["f1", "f2"])
We won't output these 50 solutions in the interest of saving space, but let's instead visualise all 50 of them using a scatter plot.
fig = go.Figure()
fig.add_scatter(x=objective_values.f1, y=objective_values.f2, mode="markers")
fig.show()
Conclusion
In this section, we covered the very basics in what we mean by an objective function. We expressed the concept mathematically and then made a direct implementation using Python. We then generated a set of 50 solutions, calculated the objective values for each one, and plotted the objective space using a scatterplot.
In the next section, we will look at a popular and synthetic objective function named ZDT1, following a similar approach where we implement a Python function from its mathematical form.