Practical Evolutionary Algorithms
A practical book on Evolutionary Algorithms that teaches you the concepts and how they’re implemented in practice.
Get the bookpractical evolutionary algorithms Single Objective Problems
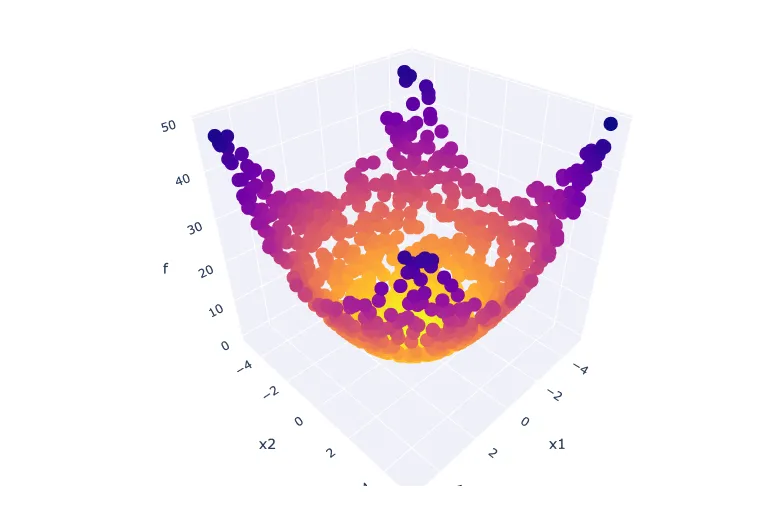
In single-objective problems, the objective is to find a single solution which represents the global optimum in the entire search space. Let's take the Sphere function as an example.

From the collection
Practical Evolutionary Algorithms
A practical book on Evolutionary Algorithms that teaches you the concepts and how they’re implemented in practice.
Get the book
ISBN
978-1-915907-00-4
Cite
Rostami, S. (2020). Practical Evolutionary Algorithms. Polyra Publishing.