
Preamble
import numpy as np # for multi-dimensional containers
import pandas as pd # for DataFrames
import plotly.graph_objects as go # for data visualisation
Introduction
Before moving on, let's take some time to have a closer look at a single-objective problem. This will give us some perspective. In single-objective problems, the objective is to find a single solution which represents the global optimum in the entire search space. Determining which solutions outperform others is a simple task when only considering a single-objective because the best solution is simply the one with the highest (for maximisation problems) or lowest (for minimisation problems) objective value. Let's take the Sphere function as an example.
The Sphere Function
This is a single-objective test function which has been expressed in Equation 1.
where
def sphere(x):
y = np.sum(np.square(x))
return y
Now let's prepare for the initialisation of five solutions with two problem variables. We will specify the desired population size,
N = 5
D = 2
D_lower = np.ones((1, D)) * -5.12
D_upper = np.ones((1, D)) * 5.12
Let's initialise a population with random decision variables.
X = pd.DataFrame(np.random.uniform(low=D_lower, high=D_upper, size=(N, D)))
X
| 0 | 1 | |
|---|---|---|
| 0 | -0.561205 | 0.705264 |
| 1 | -1.474916 | 1.087978 |
| 2 | 3.823083 | -2.378319 |
| 3 | -3.337787 | 3.081221 |
| 4 | 0.914321 | 0.390744 |
To generate sphere() test function defined above.
Y = np.empty((0, 1))
X = pd.DataFrame(np.random.uniform(low=D_lower, high=D_upper, size=(N, D)))
for n in range(N):
y = sphere(X.iloc[n])
Y = np.vstack([Y, y])
# convert to DataFrame
Y = pd.DataFrame(Y, columns=["f"])
We only have five solutions, so it's feasible to list all our objective values.
Y
| f | |
|---|---|
| 0 | 1.559800 |
| 1 | 33.985073 |
| 2 | 11.949175 |
| 3 | 10.378077 |
| 4 | 2.458470 |
We can very easily select the best solution from the above population. It is simply the solution with the smallest objective value (as we are concerned with minimisation).
np.min(Y)
f 1.5598 dtype: float64
Note
The above example relies on random numbers. This means you will see different results upon executing the code in this notebook for yourself.
Let's see if we can get a better understanding of the problem domain by generating and visualising 1000 more solutions. This means setting sphere() function.
N = 1000
X = pd.DataFrame(
np.random.uniform(low=D_lower, high=D_upper, size=(N, D)),
columns=["x1", "x2"],
)
Y = np.empty((0, 1))
for n in range(N):
y = sphere(X.iloc[n])
Y = np.vstack([Y, y])
Y = pd.DataFrame(Y, columns=["f"])
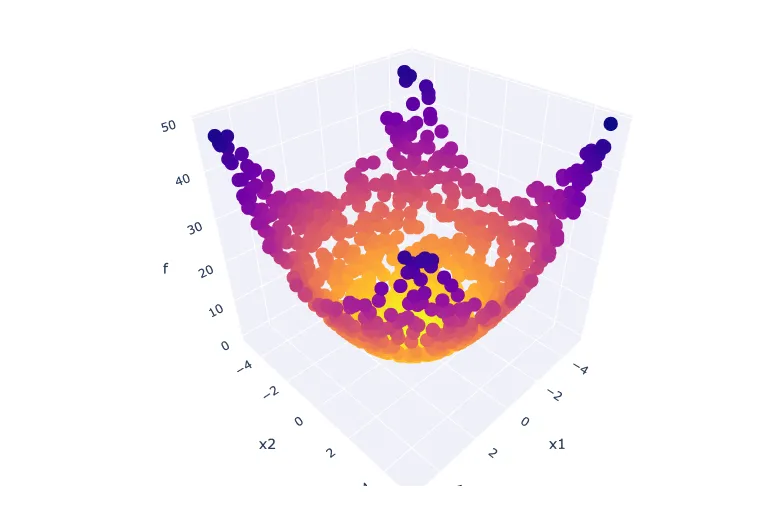
All that's left now is to visualise the results. For this, we'll use a 3D scatterplot to plot the problem variables of each solution along with each corresponding objective value. We will reserve the vertical axis for the objective value,
fig = go.Figure(
layout=dict(
scene=dict(xaxis_title="x1", yaxis_title="x2", zaxis_title="f")
)
)
fig.add_scatter3d(
x=X.x1, y=X.x2, z=Y.f, mode="markers", marker=dict(color=-Y.f)
)
fig.show()
Conclusion
In this section, we covered the very basics on the topic of single-objective optimisation problems using the popular Sphere function as an example. The most important lesson from this section is that it is trivial to determine which solution outperforms the rest when working with a single-objective problem.
In the next section, we will demonstrate why this is more difficult for multi-objective problems, and introduce some approaches to selection.
Exercise
Repeat the same experiment in this section, but this time use the Rastrigin function (Equation 2, where