Practical Evolutionary Algorithms
A practical book on Evolutionary Algorithms that teaches you the concepts and how they’re implemented in practice.
Get the bookpractical evolutionary algorithms Algorithm Performance and Statistical Significance
Let's test the significance of our pairwise comparison. The significance test you select depends on the nature of your data-set and other criteria. We will use the Wilcoxon signed-rank.

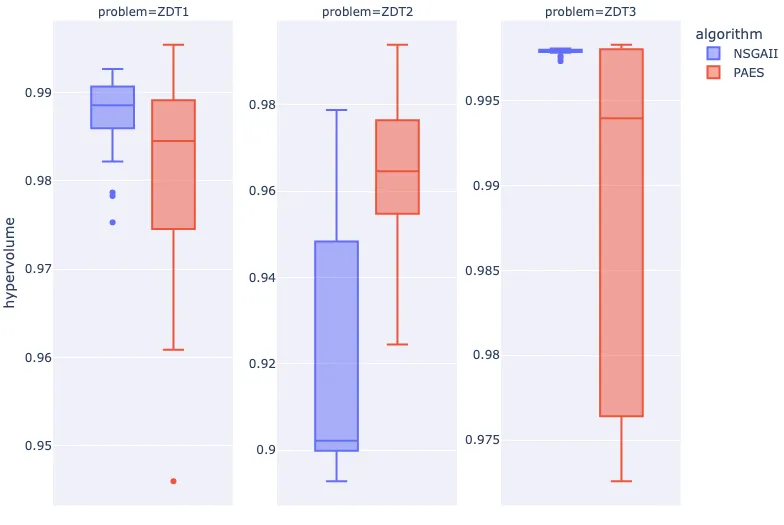
From the collection
Practical Evolutionary Algorithms
A practical book on Evolutionary Algorithms that teaches you the concepts and how they’re implemented in practice.
Get the book
ISBN
978-1-915907-00-4
Cite
Rostami, S. (2020). Practical Evolutionary Algorithms. Polyra Publishing.