

Not every sphere is a walnut.
Data analysis and visualization tutorials often begin with loading an existing dataset. Sometimes, especially when the dataset isn't shared, it can feel like being taught how to draw an owl.
So let's take a step back and think about how we may create a dataset for ourselves. There are many ways to create a dataset, and each project will have its requirements, but let's pick one of the easiest approaches - web scraping.
We'll consider one of my earlier Pokémon-themed visualizations made with PlotAPI and create a similar dataset from scratch.
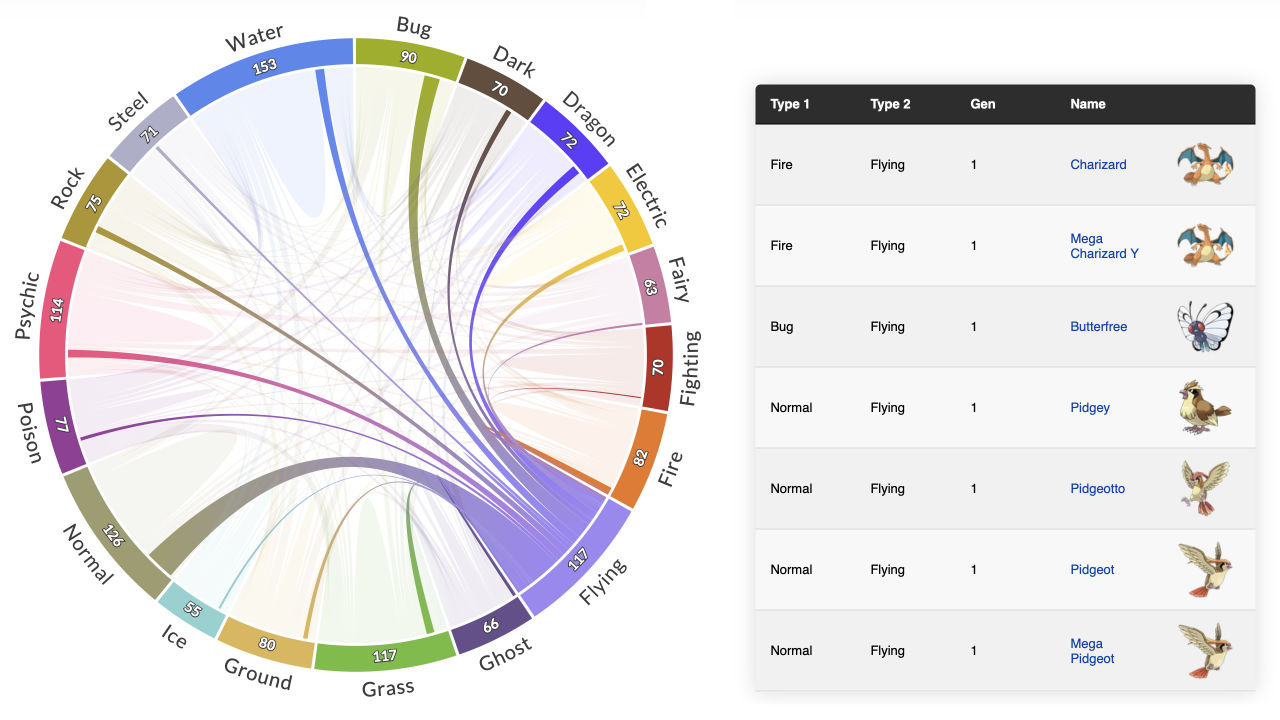
Sourcing the data
There's often no better source than something official, as it gives us some guarantees about the integrity of the data. In this case, we're going to use the official Pokédex.
When clicking on the first Pokémon, Bulbasaur, we can see the following in our address bar.
https://www.pokemon.com/us/pokedex/bulbasaur
Using a Pokémon's name to locate a resource would make automation inconvenient. It means that we'd need to substitute every Pokémon's name to collect their data, and that means having all 800+ Pokémon names available upfront.
https://www.pokemon.com/us/pokedex/{pokemon_name}
Lucky for us, we can pass in the Pokémon ID instead of the name.
https://www.pokemon.com/us/pokedex/001
Where 001 is Bulbasaur's Pokémon ID. A mildly interesting discovery is that the following will also take you to the same resource!
https://www.pokemon.com/us/pokedex/1
https://www.pokemon.com/us/pokedex/0000001
Now that we can use the Pokédex ID, we can just loop from 1 onwards to retrieve all our data!
How do we extract the data?
Now that we have a source, let's figure out how we're going to extract data on our first Pokémon.
We need to confirm a few things:
- What data do we want to extract?
- Where is the data stored in the HTML document?
So let's start with point 1. I'm planning for an upcoming visualisation, so I know I'm going after the following data: pokedex_id, name, type_1, type_2, and image_url.
Now onto point 2. This involves opening up the web page and inspecting its HTML source. The idea here is to find points of reference for navigating the HTML document that allow us to extract the data we need. In an ideal scenario, all of our desired data will be conveniently identified with id attributes, e.g. <div id="pokemon_name">Bulbasaur</div>. However, it's more likely that we'll need to find some ancestral classes that we can use to traverse downwards to the desired elements.
There's more than one way to extract the same datum, so feel free to deviate from my suggestions.
Pokédex ID
This is an easy one - as it's what we're using to look up the data in the first place! We won't need to retrieve this from the resource.
Name
Let's see where the name appears in the HTML source. I'll be using Safari's Web Inspector, but you can use whatever you prefer.
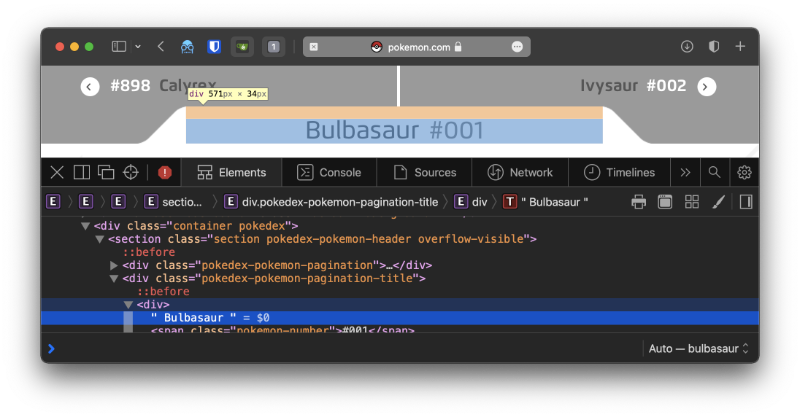
This one looks easy enough. The name appears in a <div>, with a parent <div> that has the class pokedex-pokemon-pagination-title. A quick search shows that it's the only element with that class name - so that makes it even easier!
%%blockdiag -w 300
{
orientation = portrait
'<div class="pokedex-pokemon-pagination-title">' -> '<div>'
'<div>' [color = '#ffffcc']
}
Types
Now we're after the Pokémon's type, which can (currently) be up to two different types. For example, Bulbasaur is a Grass and Poison type.
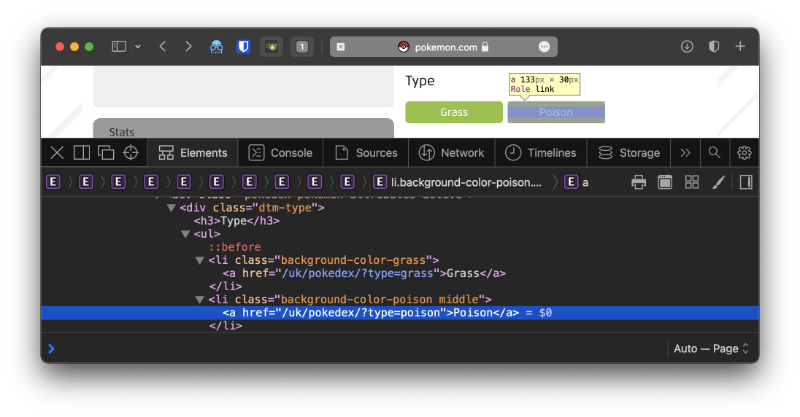
This one doesn't look too tricky either. Each type classification is within the content of an anchor tag (<a>), each appearing within a list item (<li>), within an unordered list (<ul>), and most importantly, within a <div> with the class name dtm-type. Again, a quick search shows that it's the only element with that class.
%%blockdiag -w 300
{
orientation = portrait
'<div class="dtm-type">' -> '<ul>' -> '<li>' -> '<a>'
'<a>' [color = '#ffffcc']
}
Image URL
At some point we may want to use the image of the Pokemon - I know I'll need to.
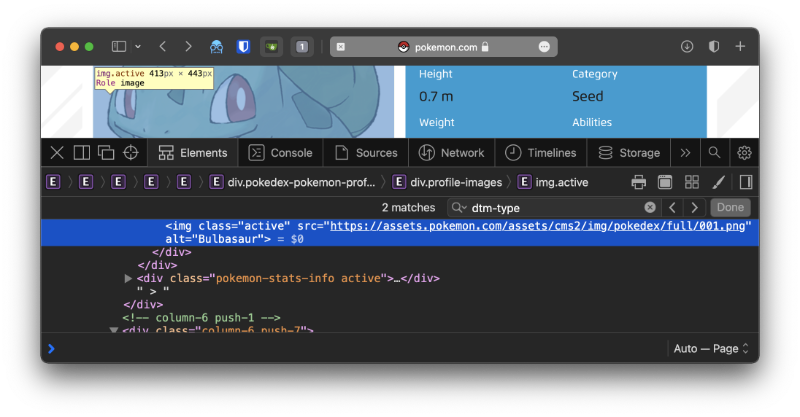
It looks like the image URL for every Pokémon has the following pattern.
https://assets.pokemon.com/assets/cms2/img/pokedex/full/{pokedex_id}.png
Where pokedex_id is a Pokémon's 3-digit Pokédex ID. Let's try for Mewtwo (#150), which should be located at https://assets.pokemon.com/assets/cms2/img/pokedex/full/150.png.

Looks like it works!
Caution
Although we've just determined how we're going to extract our desired data, this does not guarantee that the website will maintain the same document structure when it's updated. For example, the class pokedex-pokemon-pagination-title that helps us find the Pokemons name could disappear!
Extracting our data with Python
I'm going to use Python to extract this data - but you could use anything. There are many Python libraries for processing HTML, but I'm going to stick to the basics. I'll use the requests package to retrieve the HTML document, and lxml to process it and retrieve our data.
import requests
url = 'https://www.pokemon.com/us/pokedex/001'
result = requests.get(url)
html = result.content.decode()
Now, we have the HTML content of Bulbasaur's Pokédex resource in our variable named html. We could print this entire string out now to confirm, but I'll skip that and instead print out a few lines to avoid flooding this page.
html.split('\n')[6:10]
['', '', '', ' ']
It's always a good idea to confirm that we've retrieved the content we're after. Now that we've done that, let's move on to using lxml to process our document.
import lxml.html
doc = lxml.html.fromstring(html)
Name
We'll begin with the name. We determined earlier that we'd find the element with the class pokedex-pokemon-pagination-title, find its child div, and then grab the text from there.
name = doc.xpath("//div[contains(@class, 'pokedex-pokemon-pagination-title')]/div/text()")
print(name)
['\n Bulbasaur\n ', '\n ']
Looking at this output, we can see that the data we've retrieved isn't clean. So let's clean it! Let's extract the first item in the list, and then strip out all the whitespace.
name = name[0].strip()
print(name)
Bulbasaur
Much better!
Types
Let's do the same to get the Pokémon's type(s). We determined earlier that we'd look for the dtm-type class, and within it, there will be list items containing anchor tags that have the data we're after.
types = doc.xpath("//div[contains(@class, 'dtm-type')]/ul/li/a/text()")
print(types)
['Grass', 'Poison']
Looking good. We have the type(s) in a list, and we can access them individually if needed.
print(types[0])
Grass
With that, we now have a way to extract all the data we were after. Let's put this data in a dictionary so we can use it later.
pokemon = {
'pokedex_id': 1,
'name': name,
'type_1': types[0],
'type_2': types[1],
'image_url': 'https://assets.pokemon.com/assets/cms2/img/pokedex/full/001.png'
}
pokemon
{'pokedex_id': 1,
'name': 'Bulbasaur',
'type_1': 'Grass',
'type_2': 'Poison',
'image_url': 'https://assets.pokemon.com/assets/cms2/img/pokedex/full/001.png'}Getting the data into a DataFrame
Once we have our data, we may want to get it in a DataFrame and eventually write it to a CSV. We'll use pandas for this! We'll create a DataFrame and specify the columns ahead of time.
import pandas as pd
data = pd.DataFrame(columns=['pokedex_id','name','type_1','type_2','image_url'])
data
| pokedex_id | name | type_1 | type_2 | image_url |
|---|
Now we can append our dictionary earlier to this DataFrame to populate it.
data = data.append(pokemon, ignore_index=True)
data
| pokedex_id | name | type_1 | type_2 | image_url | |
|---|---|---|---|---|---|
| 0 | 1 | Bulbasaur | Grass | Poison | https://assets.pokemon.com/assets/cms2/img/pok... |
Automating the process
We've just extracted the data for a single Pokémon. Now, let's move on to automating the process and building our dataset!
We'll want to loop through our Pokédex IDs starting from #1 and going until the Pokédex ID of the newest Pokémon. However, we won't know when to stop unless we loop up the Pokédex ID of the newest Pokémon ourselves.
Knowing when to stop
I've looked up the newest Pokémon (at the time of writing this article), and it's #898. We may prefer not to do this every time new Pokémon are released, so let's automate this process first.
Our approach will be to check the response status code for our requests. Here we can see that a page exists for the latest Pokémon on the official Pokédex. This returns a status code of 200.
url = 'https://www.pokemon.com/us/pokedex/898'
result = requests.get(url)
print(result.status_code)
200
However, a Pokémon with the Pokédex ID #2002 returns a status code of 404. This is because the page doesn't exist!
url = 'https://www.pokemon.com/us/pokedex/2002'
result = requests.get(url)
print(result.status_code)
404
Great! All we need to do is continue our loop while the response status code is 200.
Generating the dataset
Let's take parts of our earlier work and piece them together.
We'll begin by setting up the empty DataFrame containing our desired columns from earlier.
data = pd.DataFrame(columns=['pokedex_id','name','type_1','type_2','image_url'])
data
| pokedex_id | name | type_1 | type_2 | image_url |
|---|
Here comes the main loop! This will start at Pokédex ID #1 and loop onwards until a page cannot be found.
pokedex_id = 0
while True:
pokedex_id += 1
url = f'https://www.pokemon.com/us/pokedex/{pokedex_id}'
result = requests.get(url)
if not result.status_code == 200 or pokedex_id > 20:
break
html = result.content.decode()
doc = lxml.html.fromstring(html)
name = doc.xpath("//div[contains(@class, 'pokedex-pokemon-pagination-title')]/div/text()")
name = name[0].strip()
types = doc.xpath("//div[contains(@class, 'dtm-type')]/ul/li/a/text()")
pokemon = {
'pokedex_id': pokedex_id,
'name': name,
'type_1': types[0],
'type_2': types[1] if (len(types) > 1) else None,
'image_url': f'https://assets.pokemon.com/assets/cms2/img/pokedex/full/{pokedex_id:03d}.png'
}
data = data.append(pokemon, ignore_index=True)
I've imposed a limit of 20 Pokémon using the condition or pokedex_id > 20. This is because retrieving 800+ Pokémon takes a long time! You can change or remove this condition in your version. Let's see what we've collected!
data
| pokedex_id | name | type_1 | type_2 | image_url | |
|---|---|---|---|---|---|
| 0 | 1 | Bulbasaur | Grass | Poison | https://assets.pokemon.com/assets/cms2/img/pok... |
| 1 | 2 | Ivysaur | Grass | Poison | https://assets.pokemon.com/assets/cms2/img/pok... |
| 2 | 3 | Venusaur | Grass | Poison | https://assets.pokemon.com/assets/cms2/img/pok... |
| 3 | 4 | Charmander | Fire | None | https://assets.pokemon.com/assets/cms2/img/pok... |
| 4 | 5 | Charmeleon | Fire | None | https://assets.pokemon.com/assets/cms2/img/pok... |
| 5 | 6 | Charizard | Fire | Flying | https://assets.pokemon.com/assets/cms2/img/pok... |
| 6 | 7 | Squirtle | Water | None | https://assets.pokemon.com/assets/cms2/img/pok... |
| 7 | 8 | Wartortle | Water | None | https://assets.pokemon.com/assets/cms2/img/pok... |
| 8 | 9 | Blastoise | Water | Water | https://assets.pokemon.com/assets/cms2/img/pok... |
| 9 | 10 | Caterpie | Bug | None | https://assets.pokemon.com/assets/cms2/img/pok... |
| 10 | 11 | Metapod | Bug | None | https://assets.pokemon.com/assets/cms2/img/pok... |
| 11 | 12 | Butterfree | Bug | Flying | https://assets.pokemon.com/assets/cms2/img/pok... |
| 12 | 13 | Weedle | Bug | Poison | https://assets.pokemon.com/assets/cms2/img/pok... |
| 13 | 14 | Kakuna | Bug | Poison | https://assets.pokemon.com/assets/cms2/img/pok... |
| 14 | 15 | Beedrill | Bug | Poison | https://assets.pokemon.com/assets/cms2/img/pok... |
| 15 | 16 | Pidgey | Normal | Flying | https://assets.pokemon.com/assets/cms2/img/pok... |
| 16 | 17 | Pidgeotto | Normal | Flying | https://assets.pokemon.com/assets/cms2/img/pok... |
| 17 | 18 | Pidgeot | Normal | Flying | https://assets.pokemon.com/assets/cms2/img/pok... |
| 18 | 19 | Rattata | Normal | Dark | https://assets.pokemon.com/assets/cms2/img/pok... |
| 19 | 20 | Raticate | Normal | Dark | https://assets.pokemon.com/assets/cms2/img/pok... |
All done! We've put together our own dataset by processing HTML that we've retrieved from an official source. I'm going to add a few more features to my version of the dataset, e.g. including the evolution data. How are you going to update yours? Related video here.