Machine Learning
A collection of articles on Machine Learning that teach you the concepts and how they’re implemented in practice.
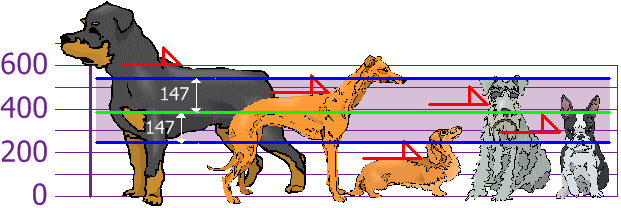
machine learning Standard Deviation
A brief re-cap on calculating the standard deviation with and without numpy.

- Previous
- Software Setup
- Next
- Pairwise Comparison
From the collection
Machine Learning
A collection of articles on Machine Learning that teach you the concepts and how they’re implemented in practice.